
Jonathan Worthington takes a glance back in time, and looks at some of the major improvements made to Comma during 2020.
Comma, Edument’s IDE for the Raku programming language, is released every month to subscribers, and a free version is also delivered quarterly. Every month, Comma improves: there’s new features, refinements to existing functionality, bug fixes, and sometimes tweaks to keep on top of the evolution of the Raku language and its ecosystem.
As Comma’s project lead, most of my thinking time on the product is about what we haven’t delivered yet, and how we can serve Raku developers better. For a moment, however, I’d like to take a glance back in time, and look at some of the major improvements made to Comma during 2020.
Integrated REPL
Starting the Rakudo compiler without specifying a program to run enters a REPL (Read, Evaluate, Print, Loop) mode, where it is possible to enter lines of Raku code and execute them. Variables and functions declared on previous lines are remembered and visible.
Providing access to the REPL from within Comma was a common request. However, just opening a terminal window and launching the Rakudo built-in REPL would not have given the level of experience we wanted to deliver. Instead, we built a solution specifically for Comma. The resulting integrated REPL offers:
Comfortable multi-line input and editing
A history of past evaluations in the session, any of which can be edited and re-run
Syntax highlighting
Auto-complete (of builtins, of symbols from used modules, and of symbols declared in the REPL session)
The same live code analysis and authoring support enjoyed elsewhere in Comma
The REPL can be found on the Tools menu. Alternatively, when working on a module file, the context menu has a “REPL using this module” option, which starts the REPL with the current module used.

Grammar live preview
Raku grammars, used for writing parsers, are one of the most popular features of the language, and naturally we aim to provide a good level of assistance with grammar development in Comma. 2020 saw the addition of a Live Grammar Preview tool. Many years ago, I wrote a Raku module called Grammar::Tracer, which dumps the paths that the parser takes, indicating successful and failed rule matches. I wrote it primarily as a proof of concept of Raku’s meta-object capabilities - but it went on to become a popular tool for Raku developers debugging why their grammar was failing to match.
Comma’s Live Grammar Preview is the result of reimagining Grammar::Tracer in the context of a GUI application. Displaying the trace of paths taken mapped naturally to a tree view. However, being in a GUI application gave some new possibilities. For example, clicking on a rule shows the part of the input that it matched, while double clicking on the input will sync the tree below to the deepest rule - effectively, the token - that matched the text. Being not only in a GUI, but also in an IDE, made it possible to offer a button to jump to the source code of the selected rule too.

When a grammar fails to match, the rules that failed are indicated in red in the trace output. The input text is also highlighted to show the area that was never successfully matched, and - leading up to it - text that was matched, but then the match discarded at a higher level (for example, because a construct started out OK, but then something went wrong some way into it).

Grammar and regex development support
The live preview was not the only thing we did for Raku developers using grammars. We also improved the navigation, code authoring, and refactoring of grammars and regexes.
When writing parsers, it is common to write an action class with methods matching up with the production rules. This actions class is typically used to build up a data structure. We made it possible to move between a production rule and its action method with a quick key combination (Ctrl+Alt+Home by default).
The relationship between action method and rule goes deeper, however. We also provide auto-completion of the captures in the production rule, as well as Go To Definition, making it easy to jump from the use of a capture to its definition in the rule, and back again.

Regexes and grammars are code, and code tends to evolve over time - meaning we need to refactor it. We developed some intentions and refactors to help with that. For example, we might have used positional captures, but realize our code would be more readable with named ones. An intention is available to turn a positional capture into a named one, and it automatically updates the usages. Similarly, one can turn a non-capturing group into a capturing one - and if it’s a new positional capture, Comma can renumber references to the captures that follow it.
For Comma Complete users, the extract refactor - previously for extracting an expression into a variable declaration, or an expression or statements into a sub or method - can now also be used to extract part of a regex or rule into a new named rule. This can be used to turn a complex regex into a more comprehensible set of named regexes that call each other, or to extract part of a grammar rule out in order to reuse it.
More code analyses
Comma analyses code as it is written. I find this quick feedback useful: it alerts me to problems at the very moment where I’m focused on that piece of code. A list of all of the new analyses in 2020 would go on for a while, so I’ll just pick out a couple of them.
One of my favorites is the indication of unused lexical variables, parameters, lexical subroutines, private attributes and private methods. These are indicated by greying out their names. The most obvious application of this feature is code cleanup: I’ve already opened modules I wrote months or years ago in a recent Comma release, and spotted dead variable declarations, leftover from earlier refactors, which I can discard.
However, I also find the feedback useful as I’m writing new code. Why is a variable I declared just a minute ago unused? Maybe I forgot about the thing I was going to do with it. Maybe I accidentally used another variable twice. Maybe I realized I didn’t need it. In a sense, the set of things I didn’t use yet is a reflection of the code that remains to be written.
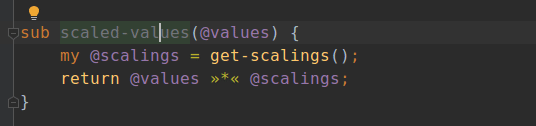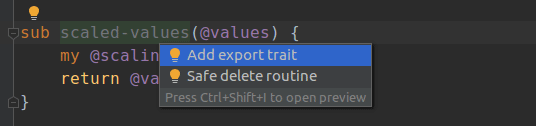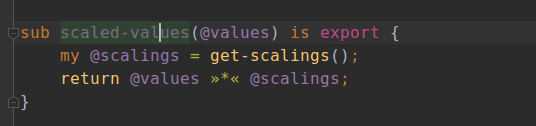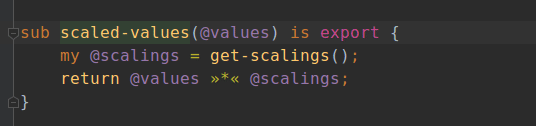
Naturally, Comma doesn’t just like to point out problems, but also to help solve them. Thus there are fixes to go with these intentions. The most obvious one is to delete the unused element. However, for subs it is possible that they are unused because we are writing a module and meant to export them - but then forgot. Thus, there’s a fix to add the export trait too.
Comma also started providing information about deprecated subroutines and methods - in the current codebase, in external modules, and in the Raku standard library. These are shown in strikeout style in auto-complete, so they can be avoided in the first place, and also marked up that way in the editor, so they can be spotted when reviewing existing code.
Improved code authoring experience
Comma tries to make the information we might need as we write code readily available. One small, but really quite handy, improvement in this area is the provision of parameter info for the automatic new method, which by default maps named parameters to public attributes. This means we can immediately see how we might initialize the object we’re creating, without having to go and look at the class definition.
Raku syntax has a range of Unicode operators and meta-operators. I find them nicer to read; when I’m working from an algorithm found in a paper or book, it’s nice to have things like the set intersection operator look just as it does in mathematical notation. Honestly, though, I’m a bit lazy about setting an input method up for that, and keeping track of them across the different platforms I might be working on. Thankfully, Comma can now translate between the Unicode and ASCII forms of operators - either on demand as an intention, or automatically as we type. It also offers this for terms like pi.

Last but not least, Comma’s code formatting is now a great deal more configurable. The default code style is pretty much how I like to see Raku code written. While my code style choices are obviously the correct ones, in a magnanimous moment I decided that Comma should cater better to those who feel otherwise. Thus, in early 2020 we finally shipped a not insignificant chunk of work to make code style far more configurable. Tinker away!

Better test running
For me, automated testing is a key part of delivering code that might just work. Thus, being able to run tests from within Comma and see the results has always been useful to me. While I don’t find it healthy to obsess over reaching 100% test coverage, finding out where there is low coverage is useful feedback, and I’m glad of test coverage support in Comma Complete also.
All of that said, there’s always room for improvement, and in 2020 we delivered some. Rather than just being able to run the whole test suite, it’s now possible to run all tests in the project, tests in a certain directory, or an individual test file. For all of these cases, it’s also possible to filter by words that should appear in the test filename. We also made it possible to set environment variables for the test run (for example, one project I work on uses an environment variable to decide whether database tests should be run or not).

Last but not least, we also made it possible to run an individual test by right-clicking on the file in the project tree and choosing to run it - without having to go through the process of creating a run configuration.
Cro template support
Cro is the most popular choice for building web services and applications in Raku. While Cro started out primarily catering to those building HTTP APIs or single page applications, it has gradually been growing a number of additional features - bundled in the Cro::WebApp module - for building server-side web applications. This includes a templating engine.
Comma already provided various features for developers building Cro applications, and in 2020 it gained early support for Cro templates also. Syntax highlighting, auto-complete, go to declaration, and other comforts one is used to when writing Raku code are also provided for the Cro template language.
And what of 2021?
Comma subscribers can look forward to receiving continued monthly releases, while those using the freely available Comma Community will continue to get a better tool once per quarter. As in 2020, there will be headline features, but also a focus on taking care of the many smaller details that contribute to a smoother and more comfortable Raku development experience.
With that said, the larger things we have in mind for 2021 include:
Lots of improvements to the profiler. We’ve already gotten started on this; the January release has a new Modules view, providing an overview of which modules most time is spent in. Information about allocations and garbage collection will soon be joining that.
Heap snapshot analysis. Rakudo can already produce heap snapshots; we will make it possible to collect and analyze them inside of Comma.
Better debugging. We’ve recently been funding some preparatory work in MoarVM to enable us to deliver a richer debugging experience in Comma.
Better support for working with the module ecosystem, perhaps including integration of producing releases using fez.
More support for Pod, the Raku documentation language, including better coverage of its syntax and a live preview.
All of which should give me plenty to write a post like this about in early 2022.
By Jonathan Worthington